How Radar uses TypeScript to manage Terraform via CDKTF
Introduction
Historically, all of Radar’s infrastructure lived in the us-east-1 AWS region and was manually provisioned by a combination of shell scripts and AWS console intervention. However, this presented a number of problems:
- Infrastructure changes involved a great deal of toil
- Infrastructure configuration was inconsistent
- Auditing and tracking lineage of infrastructure changes was difficult.
At the same time, we saw an increased demand from our EU customers for our infrastructure to be multi-region so that they could store their data in the EU.
To address these challenges, our infrastructure team evaluated tools that would enable us to quickly make infrastructure changes and solve workflow headaches with infrastructure management.
What was our solution?
We decided to use a TypeScript Terraform CDK (CDKTF) monorepo with CI/CD processes partitioned by environment (staging, production) and domain. CDKTF uses concepts and libraries from the AWS Cloud Development Kit that translates code into Terraform state files. It allows users to write infrastructure-as-code using Python, TypeScript, Java, C#, or Go.

Why did we choose TypeScript Terraform CDK?
Infrastructure as TypeScript
Since the Radar backend is primarily TypeScript and the frontend is in JavaScript, using TypeScript to manage infrastructure was a natural choice.
One of the benefits of using TypeScript to manage infrastructure is that it decreases cognitive load by reducing the number of languages our engineering team needs to understand. Type definitions in the CDKTF libraries help our engineers move fast with autocomplete and type-checking.
For instance, here is an example of Terraforming using TypeScript CDK:
const buckets = [
"com.radar.developer",
"com.radar.data",
"com.radar.infrastructure",
].map((bucket) => (
new S3Bucket(scope, `s3-bucket-${bucket}`, { bucket });
));
Compared to an example of Terraforming using vanilla HCL:
locals {
buckets = [
"com.radar.developer",
"com.radar.data",
"com.radar.infrastructure",
]
}
resource "aws_s3_bucket" "s3" {
for_each = local.buckets
bucket = each.key
}
Rather than learning about Terraform constructs, such as Terraform variables and modules, our engineers can use their existing knowledge of functions and classes. In fact, all external Terraform modules and providers are available in TypeScript via cdktf get.
Writing infrastructure code in TypeScript means engineers can construct and reference logic outside of Terraform constructs. For example, we had database configurations stored in a remote service that we were able to reuse by making an API call in TypeScript, as opposed to repeating ourselves or building a custom Terraform module. The code looked something like this:
const databaseConfig =
await databaseConfigurationService.fetch({
name: "MY_CONFIGURATION"
});
const newService = new ApiService({ databaseConfig });
In the future, our TypeScript backend codebase and infrastructure codebase may start sharing code references to normalize infrastructure sources of truth. For example, API code that publishes to a Kinesis Firehose topic can reference infrastructure definitions in CDKTF.
CDKTF Alternatives
We evaluated a few alternatives, but ultimately decided to use TypeScript Terraform CDK for a number of reasons.
1. Terraform HCL
Requiring team members to learn both a new compute paradigm and language didn’t feel necessary. In addition to the benefits of TypeScript mentioned above, we were able to perform critical portions of the workflow (plan and apply) with vanilla battle-tested Terraform tooling, so the technical risk was minimized. Instead, the main risk was ensuring that plan synthesis from CDKTF (cdktf synth) was sound. As a result, we spent a good deal of time validating this.
2. AWS CDK
We wanted to manage other clouds and infrastructure services outside of AWS, so AWS CDK was a no-go for us.
3. Pulumi
Pulumi is the initial inspiration for most CDK style tooling out today, so it seemed compelling to investigate this as a solution. However, the team decided that the stability of Terraform, the Terraform community, and our existing familiarity with the non-CDK Terraform tooling outweighed using Pulumi.
How we implemented TypeScript Terraform
CI/CD
We have parallel workflows in our CI/CD process partitioned by environment and domain.

For example, we have a staging and production workflow for our geocoding infrastructure, which includes things such as load balancers, auto-scaling groups, and EC2 instances that power our geocoding API.
On the platform side, we have separate staging and production workflows for data infrastructure, which includes Kinesis Firehose management and our Apache Airflow deployment.
Partitioning by domain and environment allows us to granularly roll out infrastructure, as opposed to risking large, shared infrastructure deployments. We can verify our changes in staging before rolling out to production.
In code, we represent separate domains as CDKTF stacks with an environment argument passed to them. For example, our staging data infrastructure stack looks like:
const dataInfrastructureStaging = new DataInfrastructureStack(
app,
"data-infrastructure-staging",
"staging",
usEast1StagingResources
);
In our CI plan step, we use CDKTF to compile and generate a plan, which gets handed off to standard Terraform tools:
#!/bin/bash
set -ex
STACK="$STACK"
S3_UPLOAD_PATH="$S3_UPLOAD_PATH"
echo "Setting up dependencies for ($STACK)"
npm ci
cdktf get
echo "Synthesizing plan ($STACK):"
cdktf synth "$STACK"
cd "cdktf.out/stacks/$STACK"
echo "Initializing terraform ($STACK):"
terraform init
echo "Planning ($STACK):"
terraform plan -out "$STACK.out"
if [[ "$S3_UPLOAD_PATH" = "" ]]; then
echo "Skipping S3 upload (S3_UPLOAD_PATH not specified)."
elif [[ "$CIRCLE_BRANCH" != "main" ]]; then
echo "Skipping S3 upload (not on main branch)."
else
echo "Uploading plan to S3: $S3_UPLOAD_PATH"
aws s3 cp "cdk.tf.json" "$S3_UPLOAD_PATH/$STACK.cdk.tf.json" # state file
aws s3 cp "$STACK.out" "$S3_UPLOAD_PATH/$STACK.out" # plan
fi
It’s worth noting above that we’re not making use of either cdktf diff or cdktf deploy. Our experience with the CDKTF versions of terraform {plan,apply} wasn’t as polished as the more battle-tested workflows, so we fed the CDKTF-generated Terraform plans to terraform plan and apply instead.
We upload the plan to S3, Amazon’s object storage, in order to ensure consistency between the infrastructure diff shown and the final changes made by Terraform.
The Terraform apply CI step looks like this:
#!/bin/bash
set -ex
STACK="$STACK"
S3_UPLOAD_PATH="$S3_UPLOAD_PATH"
echo "Downloading S3 plan ($STACK): $S3_UPLOAD_PATH"
aws s3 cp "$S3_UPLOAD_PATH/$STACK.cdk.tf.json" "cdk.tf.json" # state file
aws s3 cp "$S3_UPLOAD_PATH/$STACK.out" "$STACK.out" # plan
echo "Initializing terraform ($STACK):"
terraform init
echo "Initializing terraform ($STACK):"
terraform apply -auto-approve "$STACK.out"
We pass in the -auto-approve argument as we have a manual approval step in CI.
Provisioning new infrastructure
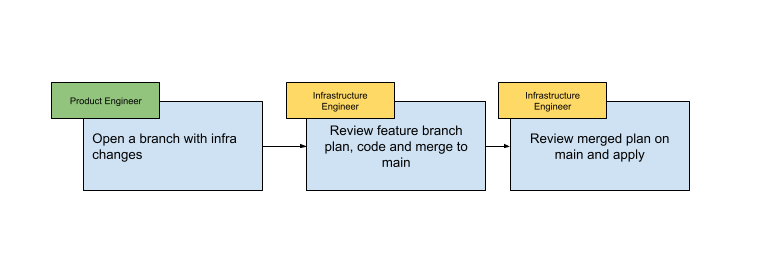
With our workflow setup, developers provision new infrastructure by making a code change and pushing to a feature branch. A reviewer from the infrastructure team reviews the code and infrastructure plan output, and then merges the code to main.
The CI/CD process runs a final plan on the main branch, reviewed by the infrastructure team. Finally, the plan is approved in CI and changes are applied to our infrastructure.
Migrating existing infrastructure
One of the biggest hurdles of adopting Terraform is the ability to migrate non-Terraformed infrastructure to Terraform. We evaluated a couple of options:
Terraform data sources
For new infrastructure that depended on pre-existing infrastructure, we used Terraform data sources. In CDKTF, these are conventionally prefixed with Data. For example, the data source of an IamRole is called DataAwsIamRole. This worked for referencing lower-level infrastructure such as VPCs, subnets, and existing security groups that we did not plan to change, but we were unable to modify this infrastructure with Terraform.
We use data sources extensively for referencing historical infrastructure and in place of cross-stack infrastructure references, which we didn’t find to be robust in our setup.
Terraform import
Terraform offers an import tool that allows remote infrastructure to be integrated into an existing Terraform state file. Given that CDKTF code would not be generated from the import, we felt importing infrastructure under our CDKTF repo would be a tough mountain to climb. Since we wanted to reduce the amount of technical risk of the initial CDKTF migration and also wanted to deliver customer value in a short timeline, we temporarily decided to avoid this.
Blue-green deploys
Ultimately, we were using the cloud, and decided that the way to approach a migration was to side-step importing existing infrastructure. Instead, we created new infrastructure under Terraform to replace the non-Terraformed versions.

In order to be safe, we took a blue-green approach where an existing service would be rewritten and managed by Terraform, and the other would be the unmanaged, historical version. This allowed us to trivially roll-back changes if we saw issues with the new version.
Depending on the service, routing traffic between services used a combination of dynamic configuration, DNS, or a load balancer. We have a strong preference of load balancing if possible, as DNS can be cached, meaning DNS changes have unpredictable immediate impact.
This gave us the ability to make risky infrastructure changes and validate them, without worrying about bringing down the entire Radar platform. Changes could be rolled back trivially. Once validated, we could route everything to the new service and remove the old one.
We continue to use this approach for any major infrastructure changes, as any additional cost is dwarfed in comparison to downtime risk and engineering hours spent mitigating said downtime. This helps us move very fast on the infrastructure engineering side.
Summary
At the end of the process, we adopted the Terraform TypeScript CDK as a means to ship data infrastructure for our EU customers in a rapid, scalable way, but have discovered additional benefits. Hopefully some of our lessons here can be applicable to your experience if you’re evaluating IaC tooling.
TypeScript for infrastructure has enabled us to move quickly on many of our initiatives. We’ve codified a number of reusable functions that have helped us add new infrastructure quickly. For example, it’s a single function call to spin up a Kinesis Firehose to our S3 Data Lake, queryable via Athena, with a configurable retention policy.
Taking a blue-green approach to infrastructure management has also allowed the team to take bigger infrastructure risks we would be otherwise afraid to do. We did this extensively in our migration to ARM64 environments, for example.
Credit to Joe Thompson for contributing to the system and to everyone who helped make this blog post happen: Bradley Schoeneweis, Jay Sani, Tim Julien, Kat Jung, Julia Parker, Hanna Woodburn.
If you’re interested in working on distributed systems, location technology, or infrastructure problems like this, check out our job postings here!