Custom Partitions with Kinesis and Athena
Introduction
Radar is the leading geofencing platform, serving over 100M api calls per day. Radar powers a variety of applications like mobile order-ahead, workforce management, and location based alerts.
Our highest throughput endpoint, /track, peaks at over 10,000 QPS. A significant amount of data exhaust is generated in the form of user events, debug location updates, and logs for our customers to gain insights on operational performance and location usage. We publish over 140 GB of daily data to Kinesis Data Firehose, which transforms the data to parquet on S3. This data is queryable with SQL using Amazon Athena.
In our old architecture, we serialized events and locations to date partitioned directories handled natively with Kinesis. This deployment worked well for us, but there were two shortcomings in the existing architecture.
First, we wanted to give customers more control over their project data by providing the ability to configure custom retention periods on the fly. This was not efficient in our existing architecture, as data across projects were mixed in parquet files, meaning we’d need to rewrite all our parquet files daily to clear out expired data.
Second, with a rapidly growing customer base, we found that queries began to slow down from data across all projects being coalesced.
We needed an architecture that would improve query performance, cost, and efficiently manage individual project-level data retention.
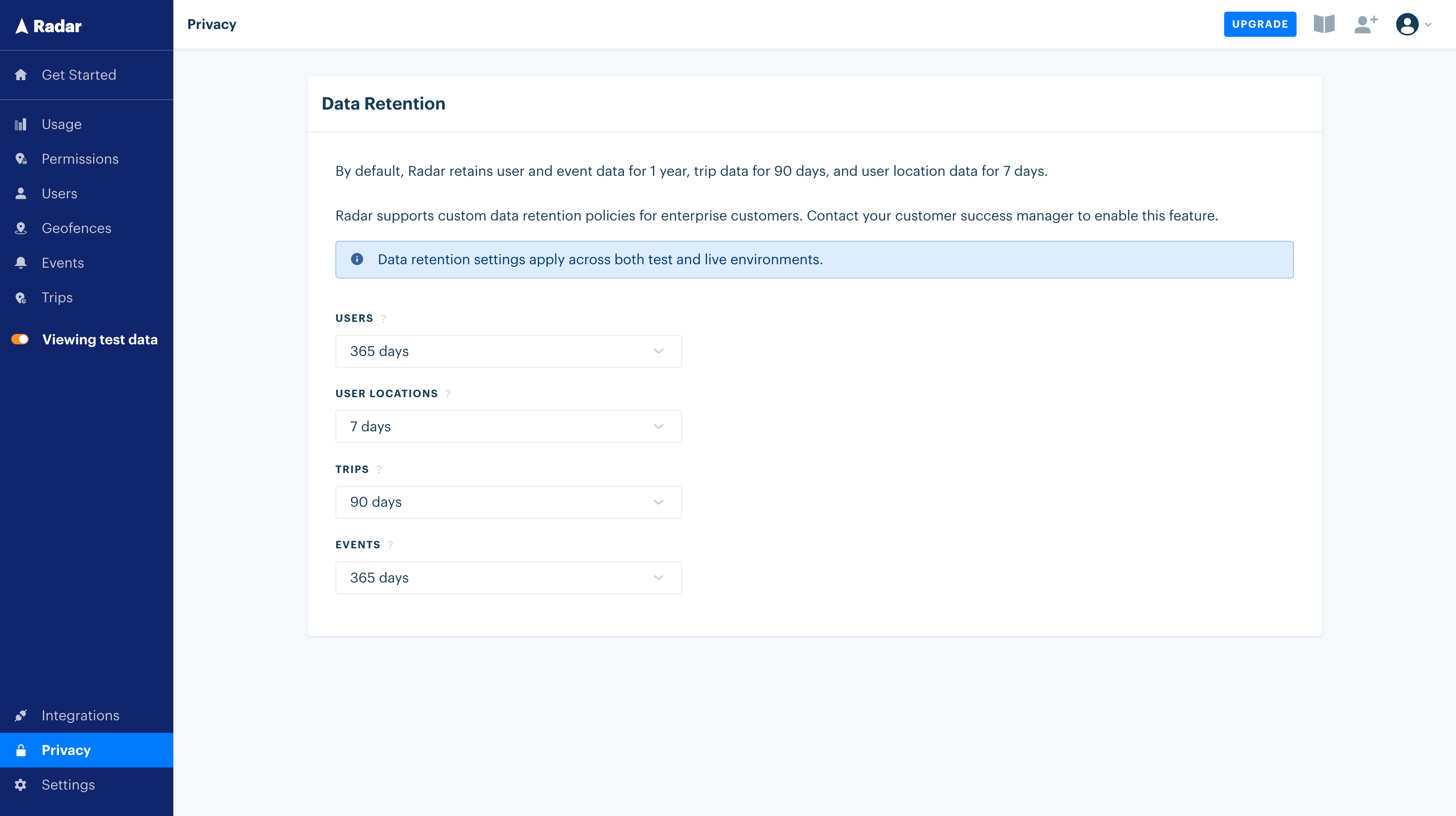
The data retention dashboard gives projects full control over the data that Radar stores.
What did we do?
Using Airflow and Athena, we built an efficient, fully-managed way of incrementally repartitioning our data to a custom key of (project, date).
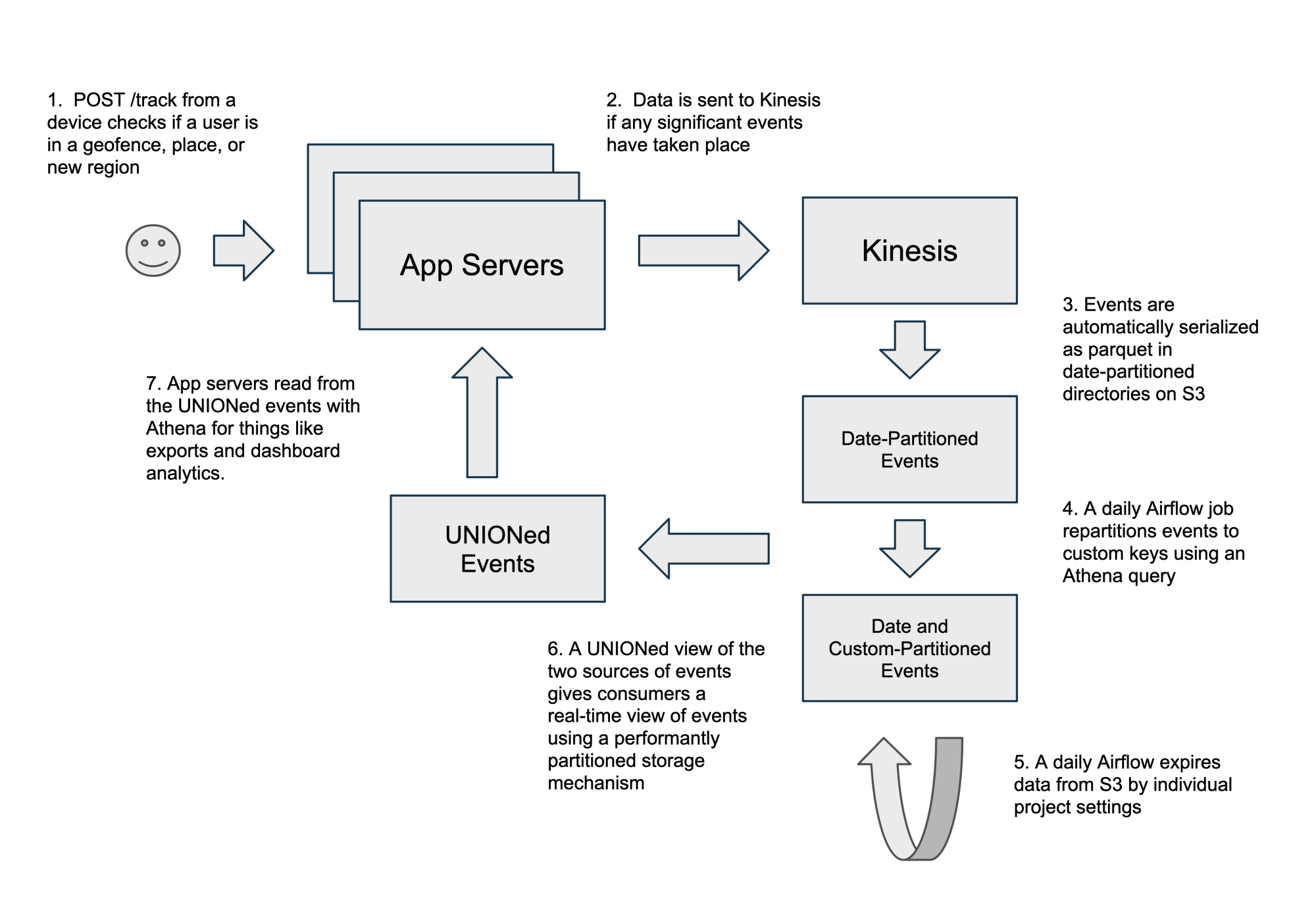
Data physically partitioned by a project and date makes it easy to dynamically manage life-cycles of individual project data. In addition, all our queries specify a project and date range, so we reduced the amount of bytes read by over 1000x in many cases. We also kept the same real-time querying capabilities that you’d expect from streamed data.
Why did we do it?
Our first instinct was to define a custom partition key natively in Kinesis Firehose. Unfortunately, it turns out that Firehose does not natively support custom partition keys. Because of that, we evaluated a few different approaches to introduce a custom partition key.
One Kinesis Data Firehose per Project
A single Firehose topic per project allows us to specify custom directory partitioning with a custom folder prefix per topic (e.g. $S3_BUCKET/project=project_1/dt=!{timestamp:yyyy-MM-dd}/).
This is a nice approach, as we would not need to write any custom consumers or code. However, we were concerned about limits in AWS and managing 1000’s of Kinesis topics.
Repartition Parquet Files with Spark Streaming
We could build a Spark Streaming Kinesis consumer to repartition data on the fly. This has some drawbacks, as it would require us to manage the up-time of this job, deal with error handling and tuning, and ensure that resources are sufficient for a growing data pipeline.
Batch Repartition Parquet Files with Spark
We could build a scheduled EMR Spark job to repartition data that lands in the output Firehose folder. This has less of an up-time concern compared to streaming, as this is run asynchronously. We’d still have to deal with writing and orchestrating the job, ensuring that partitions are evenly sized per project, and managing machines.
Batch Repartition Parquet Files with Athena
Instead of a Spark-based approach, we could make use of Athena to repartition our data. This has the same up-time characteristics as the asynchronous Spark job, but is serverless and only requires SQL. Most importantly, it means we’d introduce one less piece of technology. We ended up going with this approach and describe it in more detail in the next section.
How did we do this?
1. Define the new partition structure
In our events S3 bucket, we replaced an out-of-the-box date-partitioned directory format representing a single Athena table with two mutually exclusive sets of events backing two Athena tables:
Old structure:
events.streamed/
|_____ dt=2021-01-01/
|___________ 1.parquet
|___________ 2.parquet
...
|___________ 8.parquet
|_____ dt=2021-01-02/
...
New structure:
events.streamed/
|_____ dt=2021-01-02/
|___________ 1.parquet
|___________ 2.parquet
...
|___________ 8.parquet
events_by_project/
|_____ project=project_1
|_____ dt=2021-01-01/
|___________ 1.parquet
|___________ 2.parquet
...
|___________ 8.parquet
|_____ dt=2020-12-31
...
The events.streamed folder has a real-time stream of events automatically partitioned by date, while events_by_project stores events re-partitioned by project and date.
We represent these two partitioned folders as Athena tables like so:
Streamed table:
CREATE EXTERNAL TABLE `events`( `_id` string, `project` string, -- ...other attributes left out for brevity)PARTITIONED BY (`dt` string)ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'LOCATION 's3://com.widget.storage/events/'TBLPROPERTIES ( 'classification'='parquet', 'projection.dt.format'='yyyy-MM-dd', 'projection.dt.interval'='1', 'projection.dt.interval.unit'='days', 'projection.dt.range'='NOW-365DAYS,NOW', 'projection.dt.type'='date', 'projection.enabled'='true')
Project-partitioned table:
CREATE EXTERNAL TABLE `events_by_project`(
`_id` string,
`project` string,
-- ...other attributes left out for brevity
)
PARTITIONED BY (
`project` string,
`dt` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://com.widget.storage/events_by_project'
TBLPROPERTIES (
'classification'='parquet',
'projection.dt.format'='yyyy-MM-dd',
'projection.dt.interval'='1',
'projection.dt.interval.unit'='days',
'projection.dt.range'='NOW-365DAYS,NOW',
'projection.dt.type'='date',
'projection.enabled'='true',
'projection.project.type'='injected')
We take advantage of Athena’s partition projection capabilities, so we can dynamically and efficiently query our directory partitions. We also have a view that UNIONs the two tables in order to get the best of both worlds: efficiently-partitioned data and real-time query capabilities.
2. Create a SQL query to incrementally repartition the data
What’s nice about this approach is that repartitioning data is as simple as INSERTing to another table. Our query is simply:
INSERT INTO events_by_project
SELECT *
FROM events
WHERE dt = ‘$current_date’
Athena does the repartitioning for us automatically with the partitioned schema we’ve defined.
But wait, we’re not done yet! There is duplicate data between the two tables because we have a copy of $current_date data in both the real-time table and custom-partitioned table.
We’ll have to clean up existing data in the events table, so this is where our Airflow job comes into play.
3. Manage workflows with Airflow
We have a daily repartitioning Airflow job that does the following:
We have another Airflow job to enforce data retentions in S3:
That’s it! Now you have custom-partitioned data without writing an external spark job or using any fancy (read: complicated) streaming daemons. All of this is serverless (Athena, S3, and even Airflow comes managed from AWS now).
Summary
At Radar, we’re a high-impact engineering team working on location technology at scale. We opt for agility and lean into solutions that can help us move fast and scale to our biggest customers' needs.
We feel that our approach to custom partitioning gives us a simple, scalable solution for a problem that Kinesis users often face, and embodies engineering values we have at Radar.
In summary, for our solution:
Shout outs go to Ping Xia, Tim Julien, and Cory Pisano for designing and architecting this system, as well as reviewing this blog post.
If you’re interested in working on distributed systems, location technology, or large data problems like this, check out our job postings here!